
Redis 基础扫盲
首先,我们要对 Redis 建立一个最基本的印象,K/V,NoSQL,内存数据库,单线程。另外,Redis 还是开源的,基于 BSD 协议(这个协议允许商用),用 ANSI C 语言编写而成,能够在大部分 POSIX 系统上运行,当然最常用的就是 Linux 和 OS X 系统了。
Redis 数据类型
由于 C 语言本身缺乏对一些复杂结构的定义,因此 Redis 自定义了一些数据类型,自成体系。最基本的数据类型包括 String、List、Hash、Set、ZSet,再深入一点,就是 Bitmap、Stream、HyperLogLog 和 Geospatial。
String
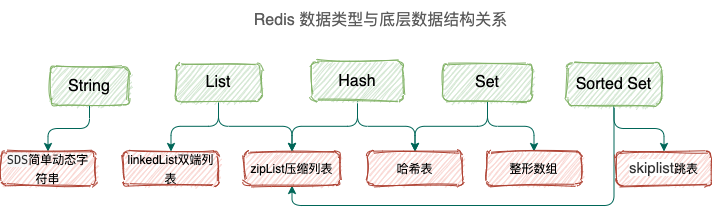
尽管 C 语言本身就有定义字符串,但是 Redis 为了存储二进制文件重新自动定义了一个 String,准确的说是用 SDS 简单动态字符串实现的,String 是 Redis 最常用也是最基本的数据类型,注意区分数据类型和数据结构,SDS 是数据结构。

List
List 可以简单当做一个双链表结构,支持双端插入和取出,不过一旦深入,就会发现它的底层并不简单。List 基本单元是 quicklist,而 quicklist 的基本单元是 ziplist。ziplist 自己又是一个特殊双链表,它使用连续块并且没有维护双指针,另一方面它保存前一个 entry 的长度和当前 entry 的长度,进而推断出下一个元素和上一个元素起始位置。为什么要这么嵌套循环设计呢?答案是为了节省内存,因为 Redis 本身是基于内存的,如果基于传统链表实现,那么肯定会产生大量内存碎片,非常浪费。

Hash
Hash 是标准的 HashTable 架构,即依靠挂链来解决冲突,如果 K/V 长度较小,Redis 会用 ziplist 取代 hashtable 对象,其他的感觉没什么好说的。

Set
Set 可以由 intset 或 hashtable 构成,原因和 Hash 类似,当一个集合只包含整数并且数量少于 512 个的时候,Redis 会使用 intset。
ZSet
ZSet 也是集合,我们在插入元素的同时要声明该元素的分数,以便它内部比较排序。然后,再谈论下它的底层结构,一般我们用 ziplist 或者 skiplist 构成,只有在元素个数少于 128 并且元素长度小于 64 字节时使用 ziplist。

跳表是在链表基础上发展而来的,为了提升查询效率,我们可以在单链表之上再加一层链表,但只保留一半,每个元素除了指向后一个元素还指向下一层的 “自己”,其可行性是建立在元素有序排列的基础之上的。当然,看到这里,我们不难想到,跳表稍微复杂点的地方是插入和删除,会以类似查询的方式对相邻元素更新。
简单来说,记住下面这张图即可
Bitmap
位图对象也是为了节省内存而设计的,如果光看手册可能不知道它该用在什么地方,其实最常见的使用场景就是海量数据统计,比如判断用户是否在线,我们可以根据用户 ID 来获取位图偏移量,对该比特位上设置用户当前登录状态。

其他应用场景:用户每月签到情况、连续签到用户总数(这里有用到 BITOP)
HyperLogLog
HyperLogLog 是用来做基数统计的,使用的时候只需要 pfadd 和 pfcount 便能添加和统计一个集合中不重复元素的数目。一想到基数统计,我们很容易想到要用集合,但由于 Redis 为了节省内存,所以并没有用 Set,也没用 BitMap,而是用了概率算法,其表现惊人,存储 1 个亿数据大概只需要 12K 内存,准确的说在误差只有 0.81% 的情况下,可以存 2^64 条数据。
一般来说,电商的 UV、PV 都会用这个统计流量。
Geospatial
Geospatial 对象是专门用来存储真实地理位置的,所以要输入经纬度。专门设计出这样一个数据对象也是为了快速计算某个位置附近的其他地标,Redis 将整个地球转换成了一个二维平面,然后将这个平面不断切割,每个坐标都位于一个唯一的小格子里,经过这个过程后一对经纬度就可以转换为一串二进制数,便于存储和计算。
Stream
Redis 持久化
Redis 作为一个内存数据库,一旦宕机,里面的数据就会全部丢失掉,而之前对 Redis 的查询请求就会直接转移到 MySQL 中。而且,要让 Redis 恢复,又要从 MySQL 中慢慢地读取,这样效率非常低。上述的两个问题,就是 Redis 持久化的意义所在。
Redis 有两种持久化方式,一个是 RDB,适合冷备,一个是 AOF。
RDB
RDB 就是 Redis DataBase,为了让 Redis 能够边复制边写入,注意 Redis 是单线程,借助了 COW,即写时复制 Copy On Write 技术。另外,由于 Redis 是由 C 语言写的,需要用到 fork 方法。当主线程接收到写入操作时,会将该数据块复制到一旁以便备份线程访问。
AOF
AOF 是 Append-only file,还是没明白什么意思,实际上 AOF 的持久化原理是将 Redis 的动作记录下来,而当宕机恢复的时候,直接重放 AOF 记录下的动作就可以快速还原。
在 Redis 4.0 后,组合了 RDB 和 AOF,组合方式也很容易想到,用 AOF 持久化上一次持久 RDB 到现在为止的动作。
数据过期清理策略
Redis 的数据过期清理策略是 no-eviction,但如果键值对们将内存撑爆了会怎样,Redis 会直接罢工的,这样的话即使请求可以一直进行但工作其实已经暂停了。
常见的过期清理策略其实不难想象,LFU 频率、LRU 最近最少未使用、Random 随机,如果设置了过期时间还可以使用 TTL 策略。
如果我们选择了 LRU,Redis 会维持一个系统时间,并且给每个键都设置一个时间值,这个时间在访问时会刷新。
队列
Redis 本身定义了 list 数据对象,也能满足一些简单队列需求。这里单独提队列,是指的阻塞队列和延迟队列。直接取空 list,取元素失败后会 sleep 一段时间再唤醒重新取,而采用 blpop 则能阻塞获取元素。延迟队列的实现也很简单,用 zset 存储消息,而把时间戳作分数,这样我们利用 zrangebyscore 在 N 秒之前对数据轮询。
发布订阅模式
这个模式有两个角色,一个负责发布频道,一个负责订阅频道,后者持续接收消息。
1 | # A is a SUB |