B 树
探讨 B 树和其变种的数据结构,比如 B 树、B+ 树、红黑树等。
起源

B 树是一种平衡搜索树,类似红黑树,但拥有更多孩子节点,这使得 B 树的高度要比红黑树小很多。因此,B 树可以在 $O (lg n)$ 时间内完成操作。许多数据库如 MySQL 就采用 B 树或其变种 B+ 树来存储信息,从而降低磁盘等辅存的 I/O 操作数。

磁盘作为辅存,区别于主存(对应内存条),是无法随机访问的,而 B 树则是专为这类无法随机访问的设备构造的数据结构。当然,随着 SSD 的大跳水,B 树也将会向着 LSM 树慢慢过渡。

硬盘或者说磁盘驱动器是由多个盘片组成的,每个盘片表面又有多个磁道,因此每次硬盘存取时间都不一样,它取决于当前磁道和所需磁道之间的距离以及初始旋转状态。不过,为了方便估计我们一般采用读写的页数来做磁盘存取时间的近似。
言归正传,由于 B 树的操作时间通常由磁盘读写时间来决定,因此我们通常将 B 树的结点设计和一个完整磁盘页一样大小。结点大小又进而限制了一个结点包含孩子个数的上限,通常是 50 ~ 2000 之间,这还取决于关键字大小。一个体现这种设计的只管例子如下,一棵结点上限为 1000 的 B 树,存储十亿个结点,高度却仅为 2。

B 树的定义
B 树和二叉搜索树、红黑树一样,将和关键字相关联的 “卫星数据” 同关键字一起放在同一结点中。当然,它一般是指针的形式,指向另一个磁盘页。之所以强调前一句,是因为一个常见的 B 树变种 B+ 树是将所有 “卫星数据” 都存储在叶子结点中的,内部仅保存关键字和孩子结点。
根据 Donald Knuth 的定义,B 树是这样一棵有根树:
- 每个结点
x有以下属性:x.n,当前存储在 x 中的结点个数。x.n个关键字本身,以非降序排列。x.leaf,一个判定当前是否为叶子结点的布尔值。
- 每个内部结点还包含
x.n + 1个指向孩子结点的指针。 - 每个关键字会对左右子树的关键字范围做切割限定。
- 每个叶子结点具有相同深度。
- 每个结点包含的关键字个数有上界和下届,用一个固定整数 “最小度数”
t >= 2去定义这些界:- 除了根结点以外的每个结点必须有至少
t - 1个关键字。 - 每个结点至多包含
2t - 1个关键字。
- 除了根结点以外的每个结点必须有至少
当 t = 2 时的 B 树是最简单的,每个结点只有 2、3、4 个孩子,即一棵 2-3-4 树。当然,我们之前也谈过了,通常这个值在 50 ~ 2000 之间。另外,根结点的关键字没有限制这一特性,跟结点插入算法为向上传播有关。
“前人栽树,后人乘凉”,任何时候都没法平地起高楼的,B 树的诞生本身也参考了 2-3 树和 2-3-4 树。B 树起源于二叉搜索树,由波音研究所的两名科学家 Rudolf Bayer 和 Edward M. McCreight 发明(1970s),应用于数据库和文件系统。B 树的 B 其实包含了多重意思,比如波音,而不是我们通常简单认为的 Balance 平衡。
2-3 tree
一棵 2-3 树由 2-node 节点或 3-node 节点构成,由 John Hopcroft 于 1970 年发明。
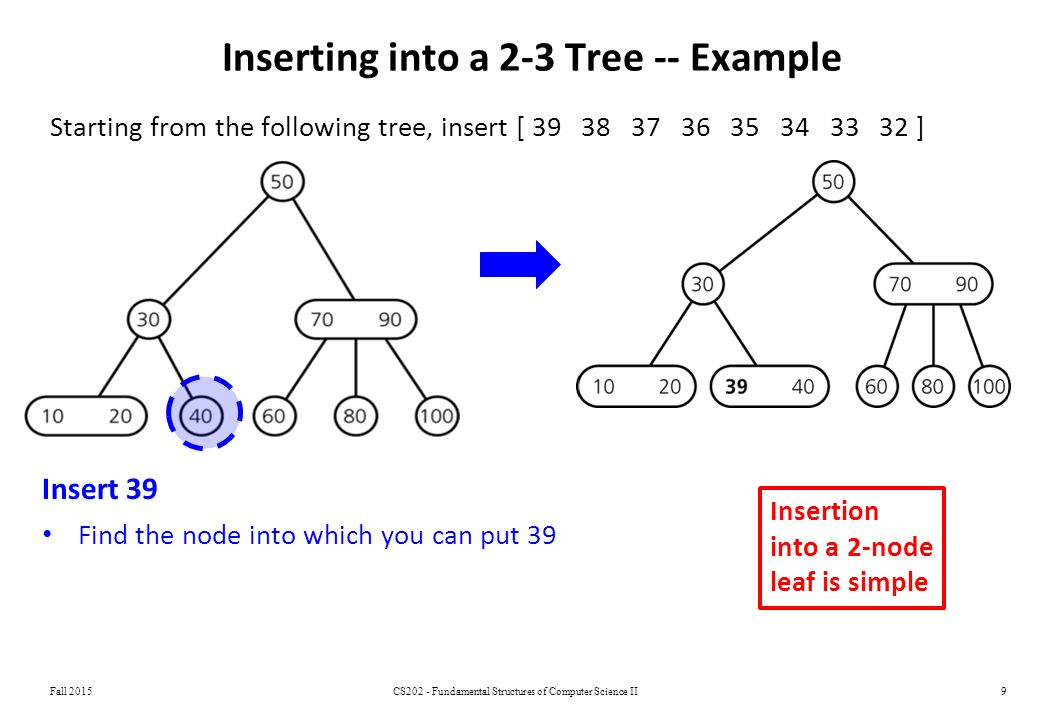
为了保持平衡,2-3 树的所有叶节点放在同一层,节点元素值也是有序排放的。
2-3-4 tree
由 2-3 树推广,2-3-4 树的内部节点还包含 4-node 节点。
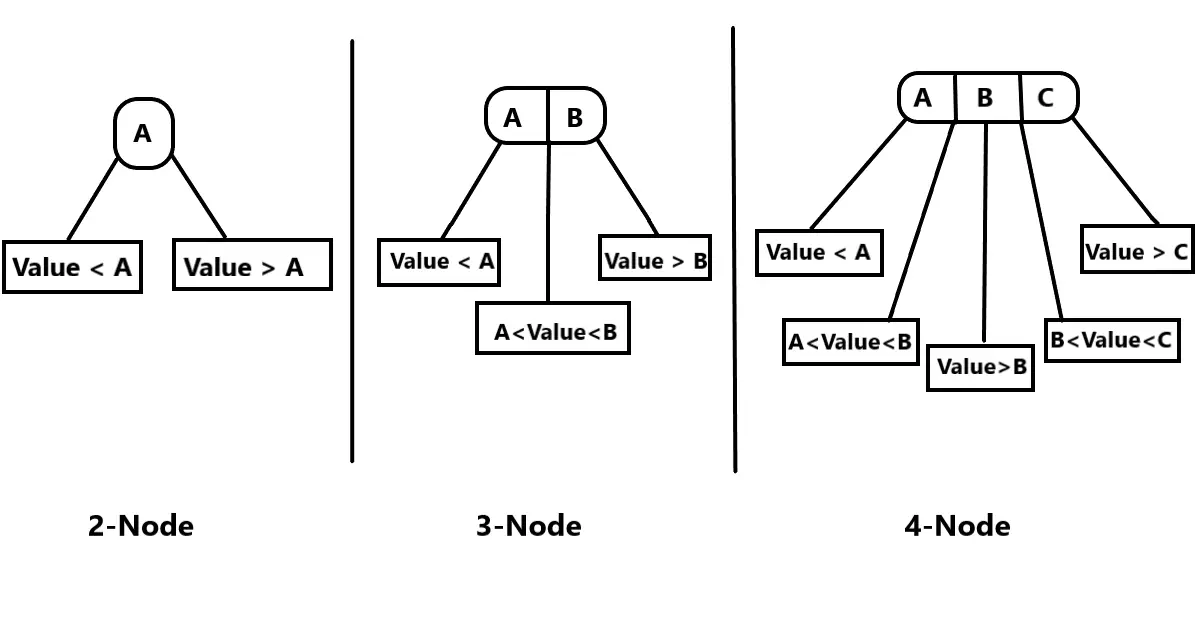
同样为了保持平衡,2-3-4 树所有叶节点也放在同一层,节点元素内部有序排列。
值的注意的是,2-3-4 树其实可以看作一棵 4 阶 B 树。
基本操作
搜索 B 树
过程和二叉搜索树类似,不断从根结点向下访问即可:
1 | def B_TREE_SEARCH(x, k): |
创建一棵空的 B 树
1 | def B_TREE_CREATE(T): |
向 B 树插入一个关键字
在 B 树中插入结点并不简单,由于不能将关键字插入一个满的结点,因此引入一个操作 ——“分裂”。分裂操作将一个满的包含 2t - 1 个关键的结点按中间关键分裂成两个包含 t - 1 个关键字的结点,而中间关键字则被提到父结点中,这是一个向上传播过程。为了将过程简化,我们在插入过程中会主动分裂满结点,从而将 “向上” 这一过程绕开。
1 | def B_TREE_SPLIT_CHILD(x, i): |
对根结点进行分裂是增加 B 树高度的唯一途径,有了上面的分裂动作,我们的插入操作也变容易起来,只需要沿树单向下行即可:
1 | def B_TREE_INSERT(T, k): |
对于一棵高度为 h 的 B 树来说,B_TREE_INSERT 要做 $O (h)$ 次磁盘存取,因为每一层只做了 $O (1)$ 次 DISK_WRITE 和 DISK_READ 操作。
删除
删除的逻辑简述如下:
- 如果关键字 k 在结点
x中,并且x是一个叶子结点,则从x中删除 k 即可 - 如果关键字 k 在结点
x中,并且x是一个内部结点,则:- x 中前于 k 的子节点
y至少包含 t 个关键字,则找到 k 在y中的前驱 k’,递归地删除 k’,并在x中用 k’ 去替换 k。 - 对称的,如果前于 k 的子结点
y只有 t - 1 个关键字,那么则找后于 k 的子结点z。 - 如果
y和z都只有 t - 1 个关键字,则将 k 和z都合并到y中,再递归删除y中的 k 关键字。
- x 中前于 k 的子节点
- 如果关键字 k 不在结点
x中,则先确定一个必定包含 k 的子树的根x.c[i]。如果x.c[i]只有 t - 1 个关键字,则:- 如果
x.c[i]的相邻兄弟包含至少 t 个关键字,则 x 中对应的那个关键字下沉到x.c[i]中, 而将相邻兄弟的一个关键字提到x中。 - 如果两个相邻兄弟都只有 t - 1 个关键字,则将
x.c[i]和一个兄弟合并,再递归删除 k 关键字。
- 如果
实现数据库索引
我们的数据库一般都放在磁盘上,而从磁盘上读取一条记录的时间大约是 10 毫秒,假设我们从一百万条数据中找到一条记录,即使用二分法也要访存 20 次即 0.2 秒。当然由于我们访存时会按块存取,而一个块可能包含连续一百条记录,这样后续的几次比较实际上并不需要访存。因此,访存时间缩短为 0.14 秒左右。
有利自然有弊,虽然我们访问记录的速度快了,但维护这样一个有序结构也变得麻烦起来。因此,当我们删除时,我们只是将其标记为已删除而暂时不动它,等访问效率降低到一定程度后再整理。同理,插入时,我们直接替换掉那些已删除的元素。而为了让删除和插入的代价尽量小,我们也需要尽量让 B 树维持在一个半满的状态。
这时候,采用 B 树作为数据库索引结构意义出现了。假设我们构建一个 100 阶的 B 树,并让它保存_一百万条数据,那么我们访问一条记录只需要 3 次_,也就是 0.03 秒。
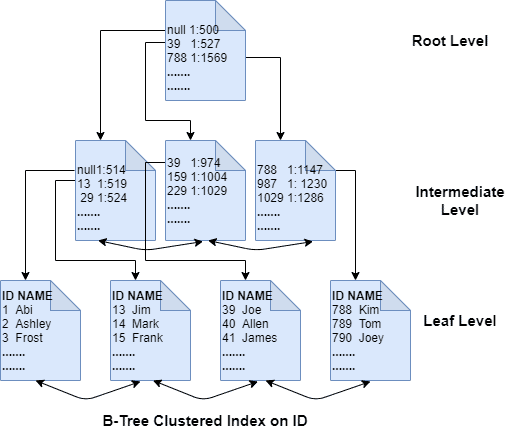
B 树用在数据库有这样几点优势:
- 有序存储键值,便于顺序遍历。
- 使用分层索引,最大限度地减少磁盘读取次数。
- 使用部分填充块来加快插入和删除的速度。
- 通过递归算法保持索引平衡。
此外,B 树通过确保内部节点至少半满,最小化浪费,B 树能够处理任意数量的插入和删除操作。
衍生数据结构
B+ Tree
MySQL 的 InnoDB 采用 B + 树存储索引,相较于 B 树,由于元素都放到了叶子节点所以树会变矮查询速度变快,另一方面 B + 树的叶子节点是有序串联的,因此范围查询起来也比较方便。
红黑树 Red–black Tree
红黑树是由 Leonidas J. Guibas 和 Robert Sedgewick 在 2-3-4 树上发展而来,增删查改节点的时间都是 $O (log n)$。
红黑树保证根和叶子节点都是黑色,红色节点不相邻,且任意路径的黑色节点数相等,这使得最长路径和最短路径只有两倍差。
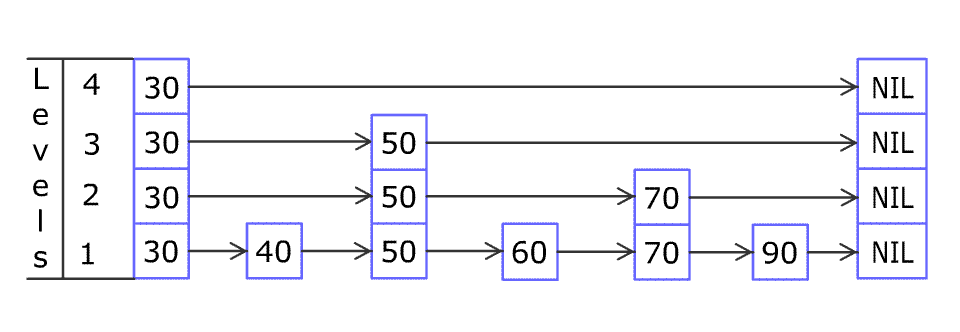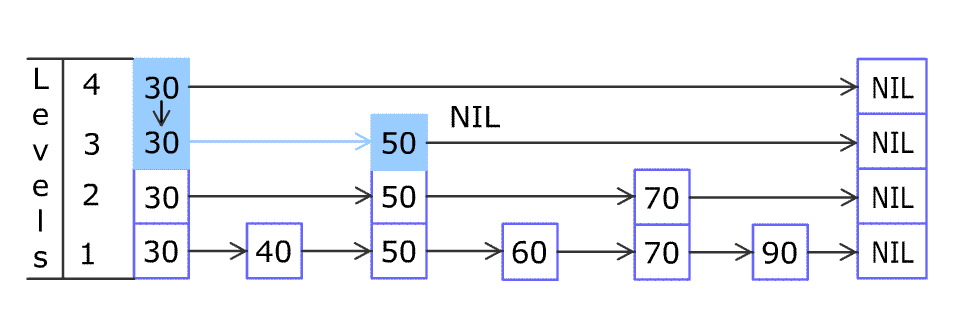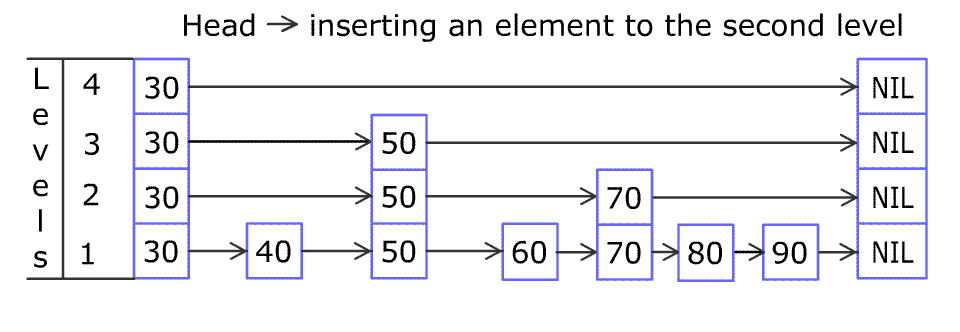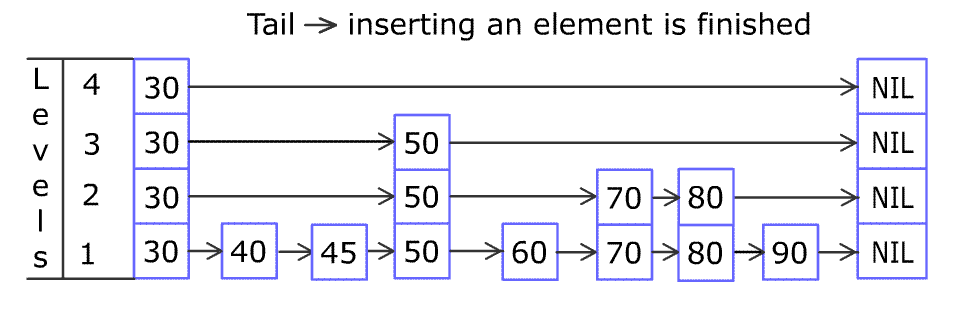
跳表 Skip list
跳表是一个概率数据结构,最大亮点是能够以 ${\mathcal {O}}(\log n)$ 复杂进行查询和增删。它实现快速查询的原理其实很简单,在维持更少元素的子序列上查找即可,这样就能跳过非目标的元素了。