
Java 扫盲(二)集合
介绍 Java 集合相关,如何设计,为什么这样设计?主要从存储和速度两个方面考虑。
Java 1.2 版本后通过 java.util.Collection 和 java.util.Map 解决了两个问题:统一管理容器对象,而不用像以前那样各种 API 满天飞,最直观的感受是程序员在算法中用起来很顺手;容易拓展,我们可以很方便地构建一个类似的自定义数据结构。
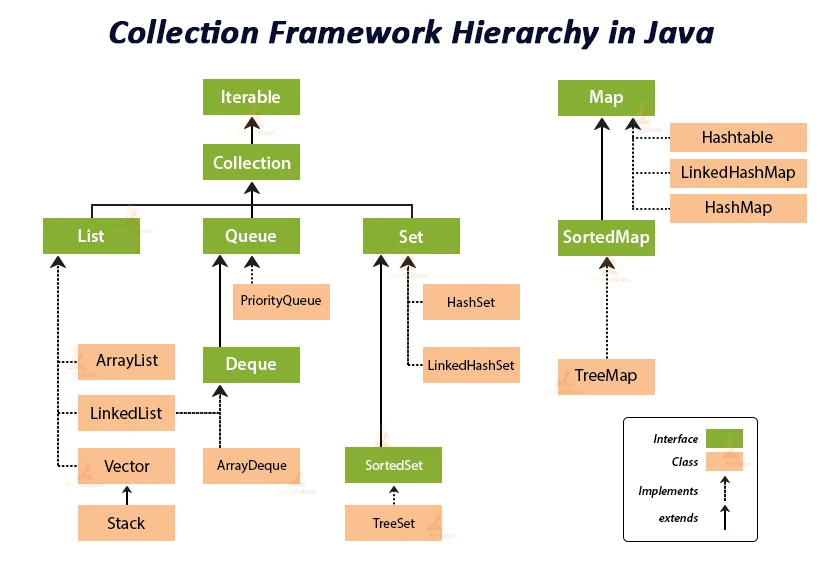
观察上图,其实可以得出很多观点,比如:
- List、Queue 和 Set 都实现了 Iterable 接口,这表示它们都可以遍历,事实上 Set 甚至可以排序(SortedSet)。
- LinkedList 模糊了 List 和 Queue 的界限。
ArrayList
ArrayList 就是一个动态数组,那我们都知道数组本身是一个固定不变的数据结构,其 “动态” 是如何体现的呢?很简单,直接创建一个新的更大的数据结构去装更多的元素,这个更替过程我们通常称之为 “扩容”,实际上是一个很简单也很直接的概念。
当然,虽然支持动态扩容方法很简单,但这样做我们很快就会遇到以下问题:
- 什么时候扩容?装不下了就扩容,之所以这里提一嘴,是因为 HashMap 扩容是由负载因子决定的,负载因子就是可容纳元素上限除以哈希表长度。
- 如何扩容?1.5 倍扩容,当然这个值本身可以自定义,通常我们会让其 2 倍扩容,将初始容量设置成一个 2 进制的数而不是原来的 10(10 的初始值主要方便了 1.5 倍扩容)。
- 如何保证数据安全?比如一边在扩容数组,另一边在删除某元素,这里就涉及到 fail-fast 机制。
fail-fast 机制
TODO
HashMap
TODO