
MIT 6.NULL 版本控制 (Git)
Version Control Systems (VCSs) 版本控制系统 是专门用来跟踪源码变动的工具。
VCSs 会用快照将文件夹和它里面的内容变化记录下来,每一份快照都完整包含了那一时刻文件夹及其子文件和子文件夹的状态,以及快照创建人信息和快照捎带信息。
版本控制有什么用?即使只是独立开发,通过 VCS 我们也能轻松了解某段代码的设计和修改目的,从而解放大脑,而在多人合作的场景下则需求更迫切:
- 谁写的这个模块?
- A 文件的第 2306 行代码是谁写的?什么时候写的?为什么这么写?
- 之前某个功能单元是能正常运行的,但现在无法运行了,我该去哪里找问题?
- 甲部门开发 x 功能,同时让 Z 部门开发 y 功能
Git 数据模型

这个漫画讽刺了 Git 的接口设计,太过抽象容易让人困惑,以至于最后大家都像念魔咒一样用它。但如果我们自底向上,先去了解 Git 的底层设计,也就是 Git 数据模型,理解起 Git 的运作来会更加的轻松。
理解 Git 数据模型,意味着理解 tree、blob、commit。在 Git 数据模型 中,我们将文件称为 blob,目录则称为 tree。显然,tree 可以同时包含 tree 和 blob,而 blob 并不能。还有一个我们不能忽视的角色是快照,它们被称为 commit,每个 commit 都包含以下内容:
parentauthormessagesnapshot这里指代最顶层 tree 的快照
Object
如果用伪代码表述的话,可以表示上述三者为:
1 | // a file is a bunch of bytes |
我们用 object 去统称 tree、blob、commit,则所有 object 都可以按如下方式统一管理:
1 | type object = blob | tree | commit |
简而言之,Git 会对 object 通过 SHA-1 哈希值 (40 个 16 进制数)进行内容寻址。
Reference
尽管所有的 commit 都被哈希值唯一标记,但正常人类是没办法记住 40 个 16 进制数的,因此我们需要借助索引去记忆,它们指向实际的 commits,比如我们常用索引 master 就指向主分支上的最新的 commits。
1 | references = map<string, string> |
在 Git 中,索引 HEAD 指向当前位置。
Snapshots
每个 commit 都会记录最顶层 tree,形如:
1 | <root> (tree) |
而 commits 的 DAG (有向无环图)则构成了 Git 的历史记录,通俗来讲就是,每个 commit 只需要知道自己的父亲是哪些 commits,也就是能正确回答我从哪里来这个问题就好(嗯~ 非哲学范畴)。
假如考虑这样一个场景,我们要对源码进行 1. 修复 Bug;2. 添加新功能,我们可以用新建两个分支同步执行:
1 | o <-- o <-- o <-- o |
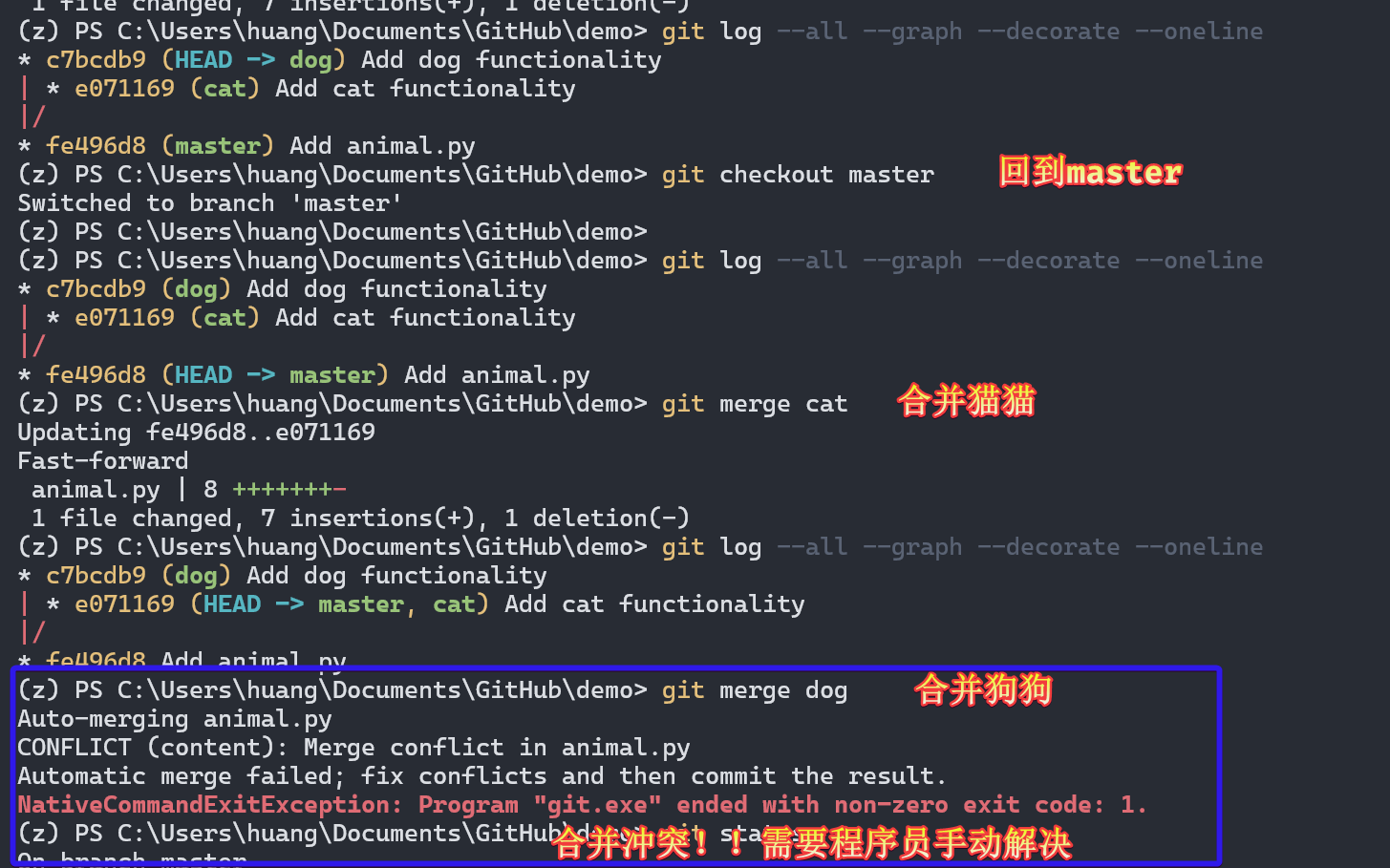
我们接下来需要合并 1 和 2,但不可避免的会遇到合并冲突,这需要我们手动选择保留和删除冲突代码。
1 | o <-- o <-- o <-- o <---- o |
Repositories
现在,我们终于能够正确定义一个 Git 仓库了!在硬盘上,它是一堆由 reference 和 object 构成的数据,我们可以从 Git 数据模型 角度去理解。我们输入的 Git 命令 都在操作 commit 的 DAG,本质上是在添加和修改 object 和 referance。
暂存区
Git 还有一个暂存区的概念,它跟数据模型正交,属于创建提交的一部分。简单来说,暂存区允许我们告诉 Git 下一次快照需要包含哪些修改,这和通常的 VCS 直接保存当前状态有所区别,这能够暂存区的快照更干净、更聪明。
另外,如果你创建了一个新文件,Git 并不会跟踪它,此时它的状态是 Untracked files,除非你用 git add 命令将其加入 暂存区。
一个高质量的提交消息很重要,可参考
Git 命令行接口
可以阅读 Pro Git 以了解更多细节。
基础
git help <command>帮助文档git init将当前文件夹初始化为一个 git 仓库,并将数据都放到 .git 文件夹 中git status查看当前状态git add <filename>添加文档到暂存区git commit创建一个commitgit log展开历史日志git log --all --graph --decorate以 DAG 方式展开历史日志git diff <filename>展示 暂存区 中该文件的具体变动git diff <revision> <filename>展示不同快照间该文件的变动git checkout <revision>更新 HEAD 索引 到指定快照
分支与合并
git branch展示分支git branch <name>创建分支git checkout -b <name>创建分支并切换 HEAD 到该分支- 等效于
git branch <name>; git checkout <name>
- 等效于
git merge <revision>将指定分支合并到当前分支git mergetool一个工具,用来解决合并冲突的git rebase变基 TODO
远程访问
git remote展示远程仓库git remote add <name> <url>将一个远程仓库添加到当前 Git 仓库git push <remote> <local branch>:<remote branch>发送objects到远程仓库,并更新远程仓库referencegit branch --set-upstream-to=<remote>/<remote branch>设置本地分支和远程分支的联系关系git fetch从远程仓库获取objects/referencesgit clone将远程仓库下载到本地
撤销
git commit --amend修改一条commit的内容或者捎带信息git reset HEAD <file>取消暂存文件git checkout -- <file>丢弃改变
Git 高级命令
git config可以参考 git-configgit clone --depth=1浅克隆,丢掉完整的历史,只保留一个快照git add -pgit rebase -igit blame查看谁最后编辑的git stashgit bisect.gitignore指定哪些 untracked files 需要忽略
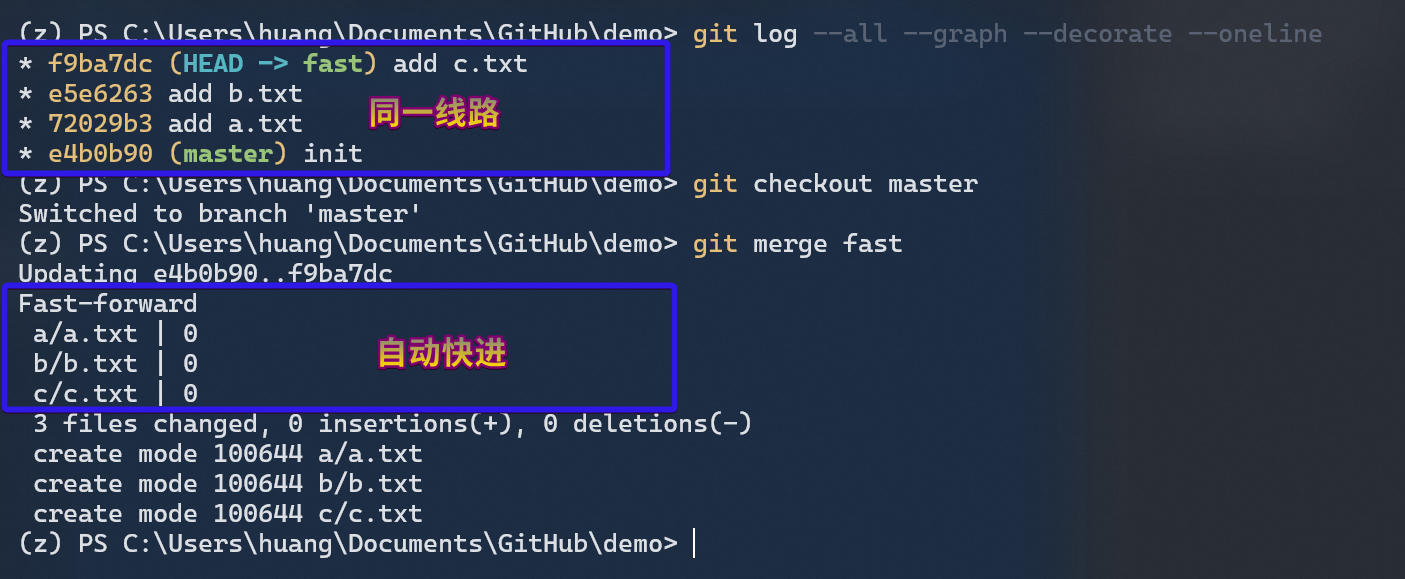
Fast-Forward Merge
**Fast-Forward Merge(快进式合并)** 其实并不需要我们做额外操作,它是 Git 本身内置的。
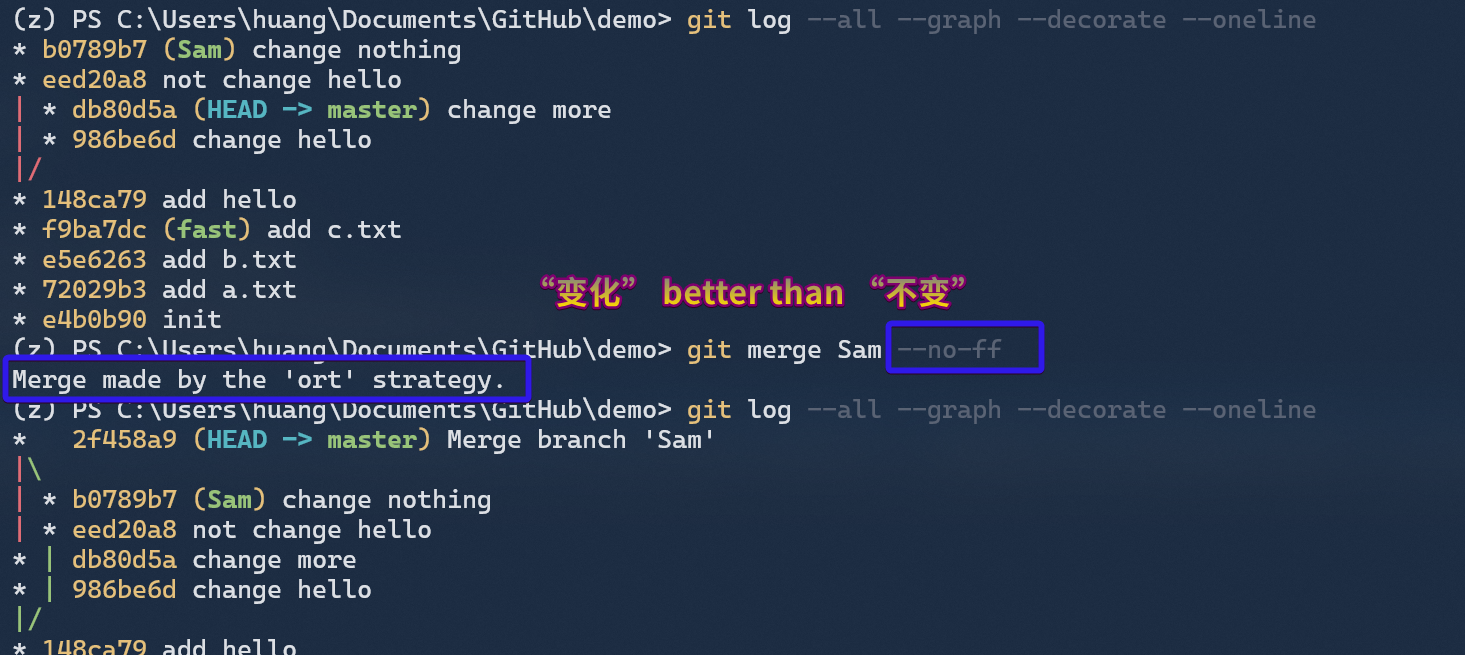
Three-Way Merge
如果在合并时使用 --no-ff 参数,Git 就会采用 Three-Way Merge(三方合并)。所谓三方合并是同 “先 diff,再手工决定” 的两方合并相区别的,它会根据原始文档内容判断到底该保留谁的,简单来说是舍旧迎新策略。
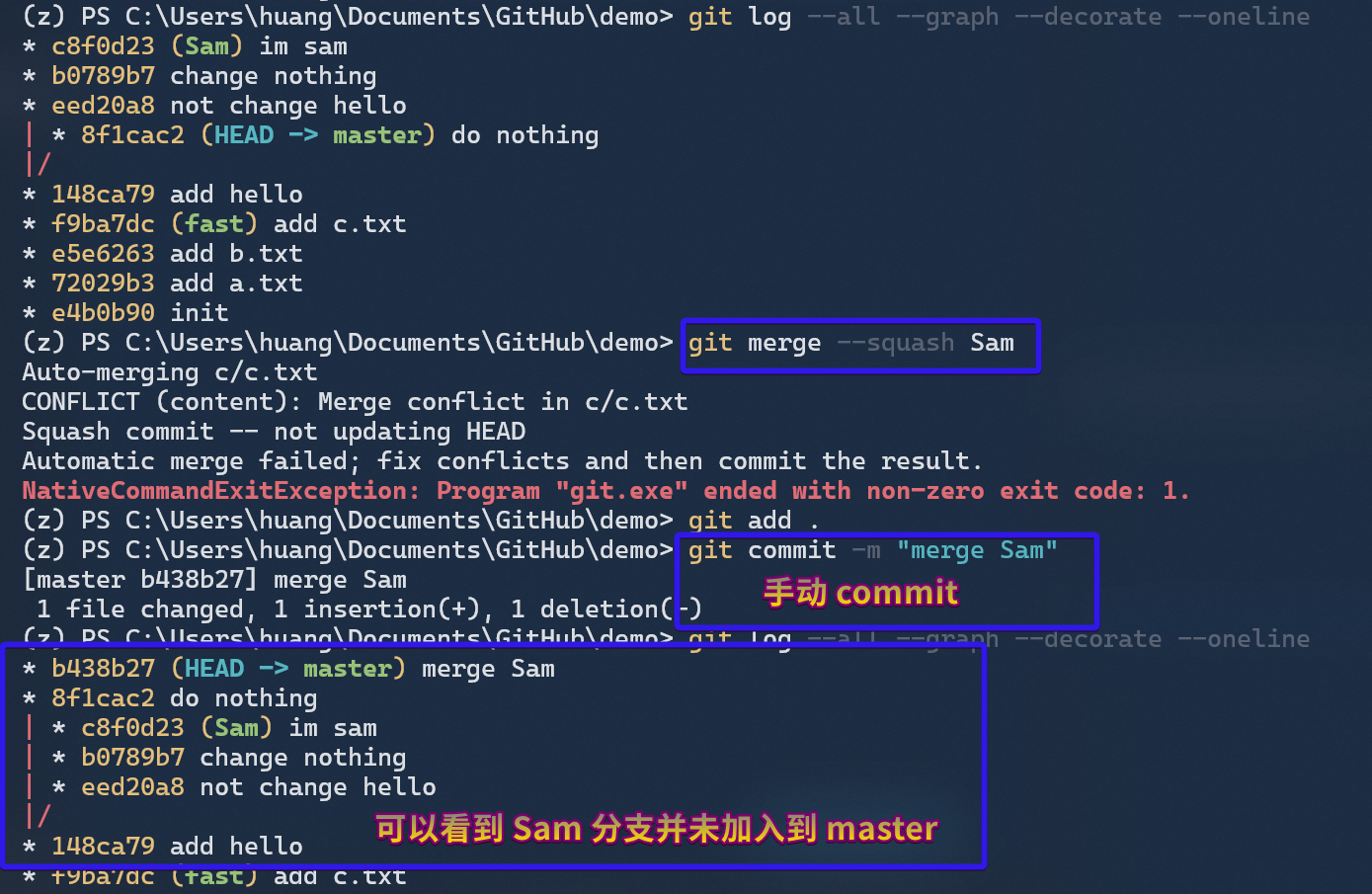
Squash Merge
**Squash Merge(压缩式合并)** 本身和普通 merge 没什么两样,但是它能让整个 log 更加干净。我们正常合并会让新 commit 拥有两个父节点,但很多时候我们的分支只是做了一些很细小的修改,如果直接 merge 会让整个 log 看着非常乱,而压缩式合并能够解决我们这种需求。当然,它是原理本身不难猜到,就是将分支改动在主干上重放,然后需要手动 commit。
Rebase
TODO
cherry-pick
TODO
Resources
- Pro Git 很重要的一本书
- Oh Shit, Git!?! 教你如何处理常见 Git 错误
- Git for Computer Scientists
- Git from the Bottom Up 详细描述 Git 自底向上实现
- How to explain git in simple words?
- Learn Git Branching Git 教学游戏
实践 1 本地操作
添加一个 animal.py
1 | import sys |
加入到暂存区
git add animal.py
提交
git commit
查看
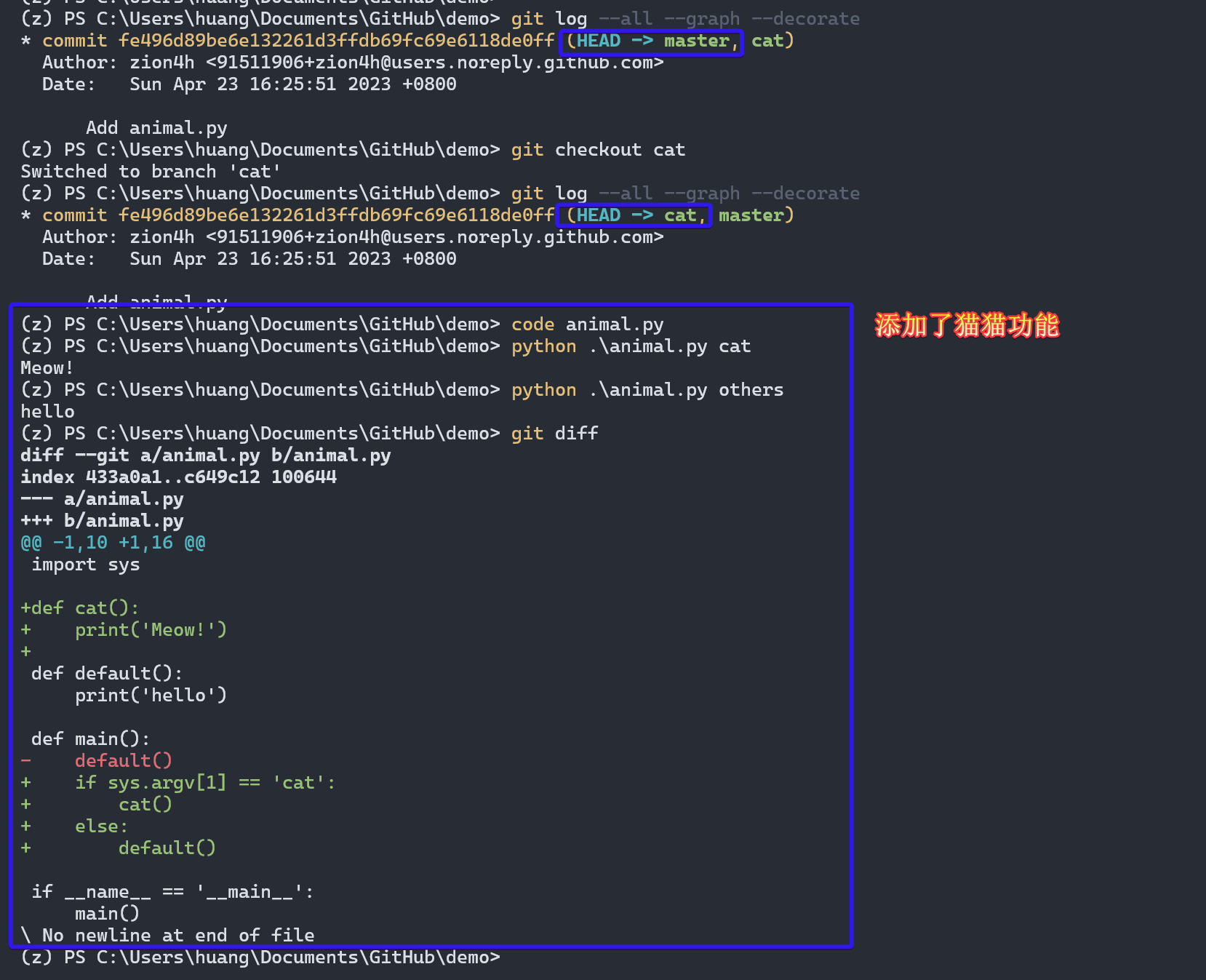
添加猫猫功能
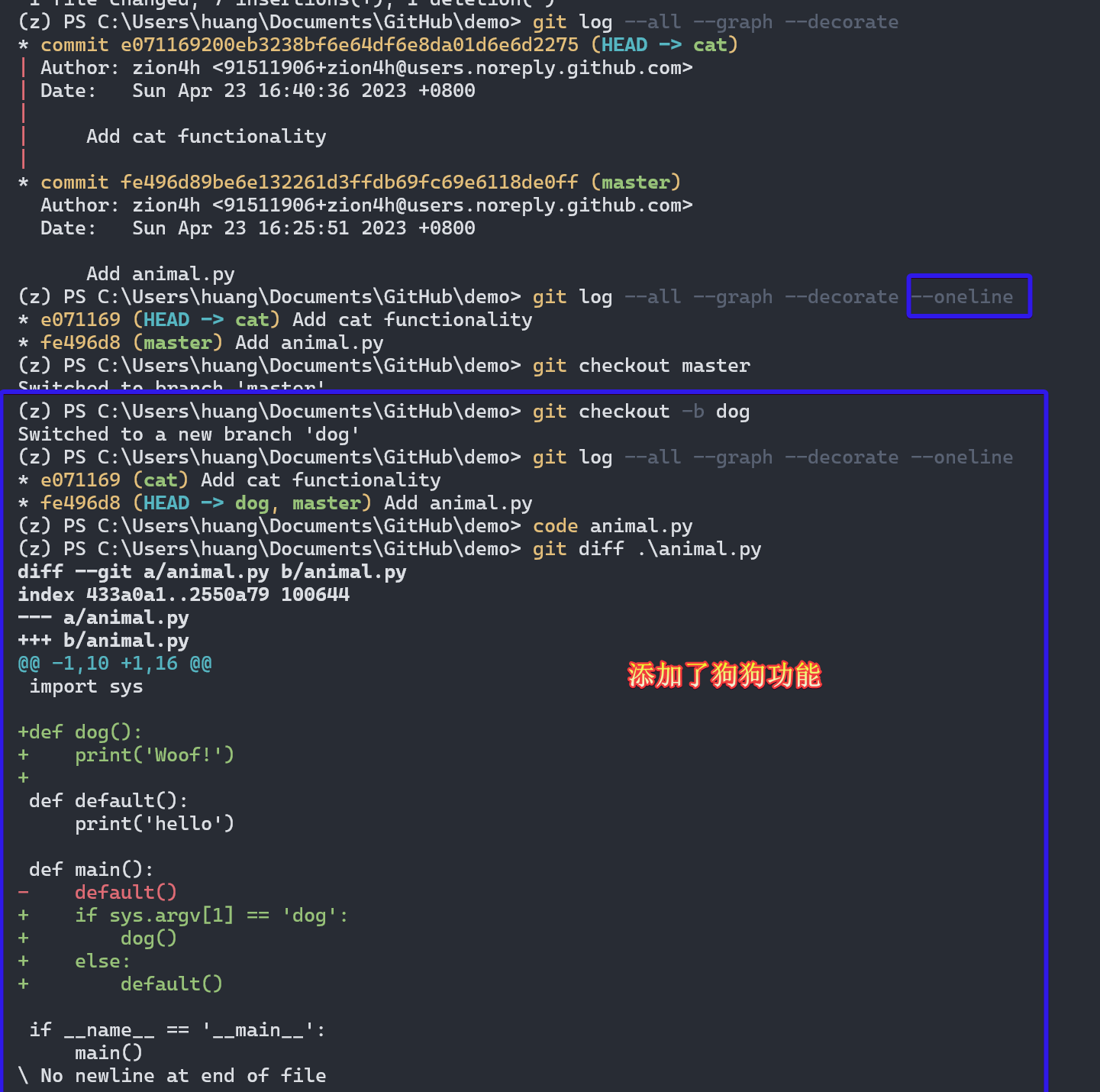
添加狗狗功能
合并分支
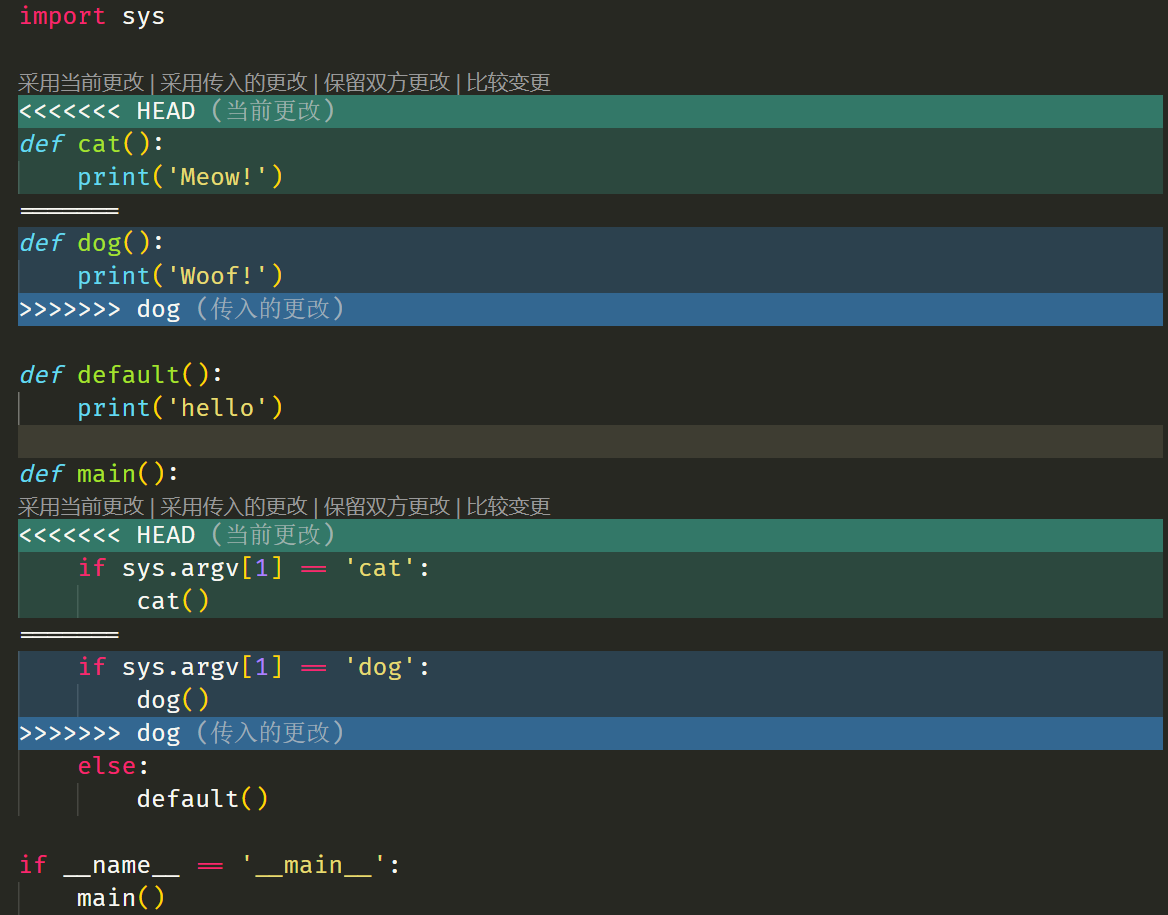
代码冲突解决后记得将冲突文件添加到暂存区,最后键入 git merge --continue,解决!
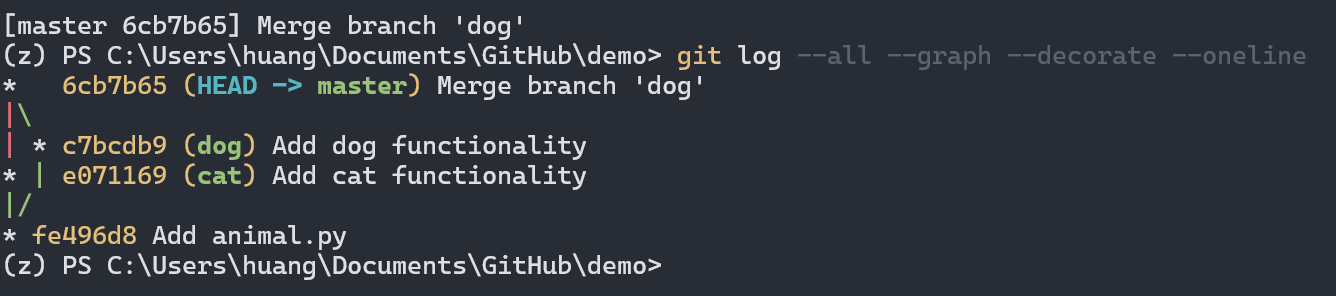
实践 2 远程访问
绑定远程项目
将本地 git 项目和远程项目绑定,如果是从远端拷贝到本地,那直接克隆就好。但若是先建立的本地项目,想要发送到远程,则需要配置 remote,再 push。
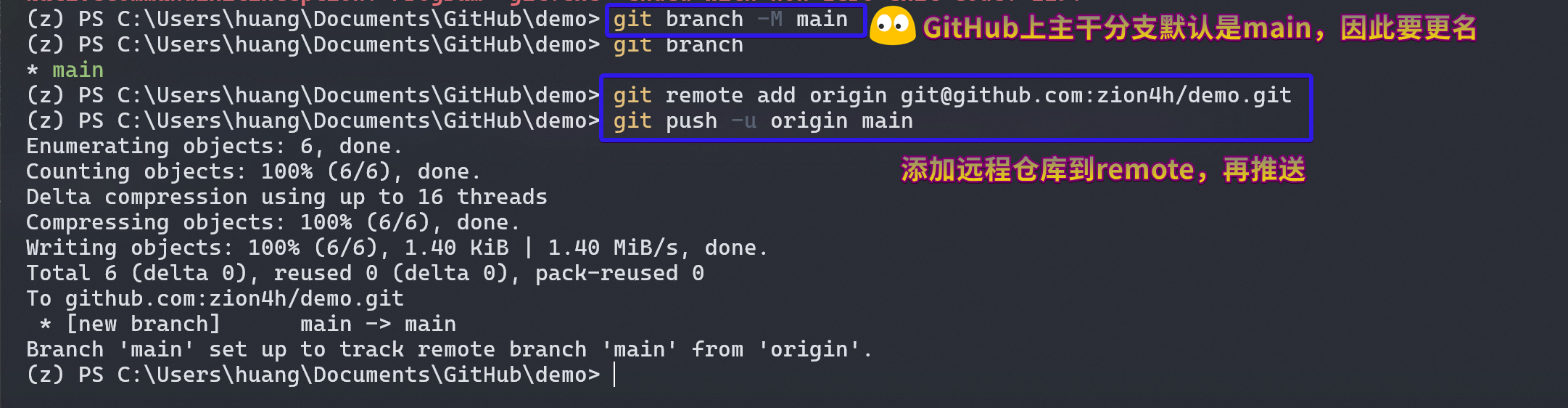
同步更新
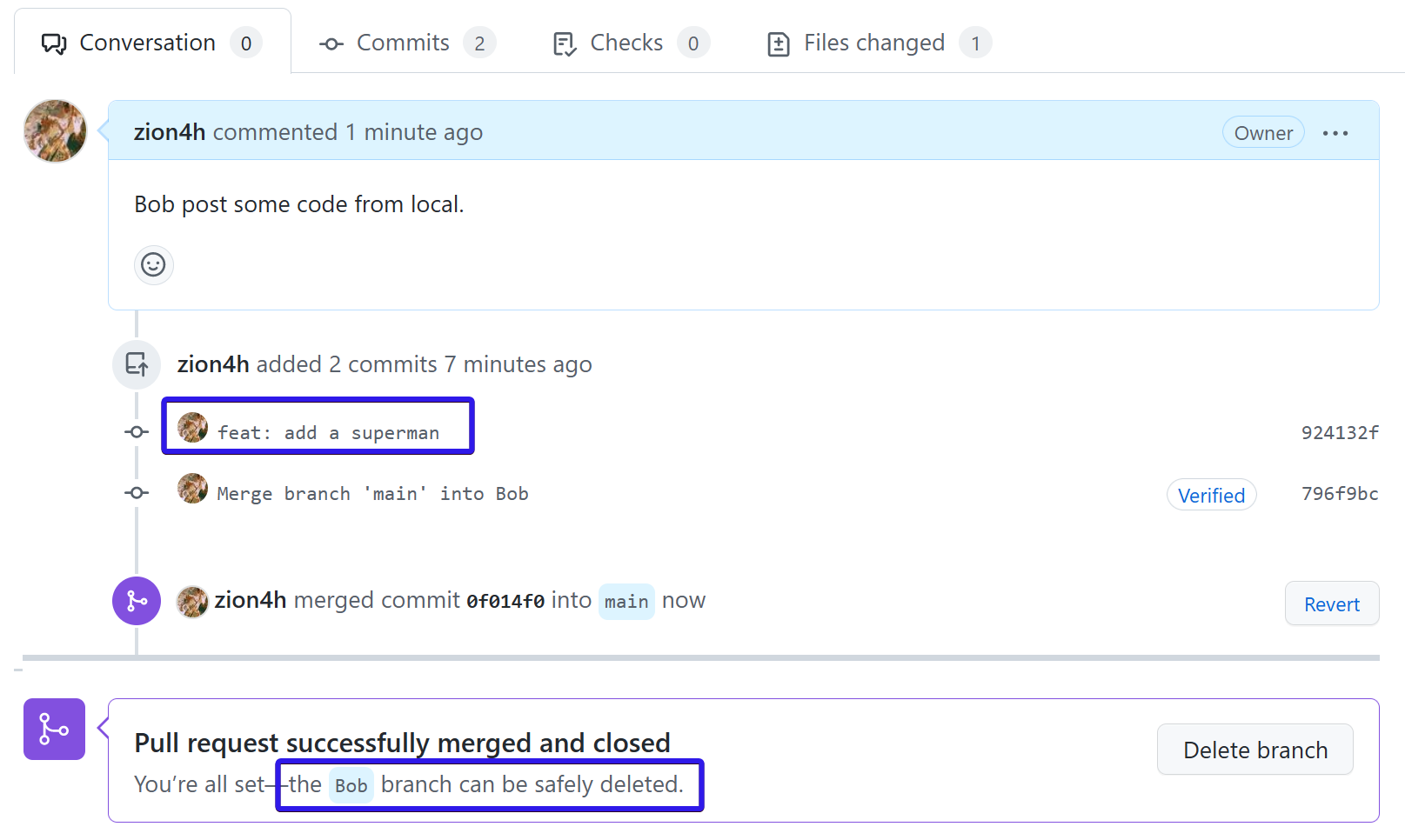
你在修改代码的同时,别人也在修改代码,因次我们除了保持本地与远程同名分支代码的同步外,想要合并到主干分支,务必请求 pull request 简称 PR。
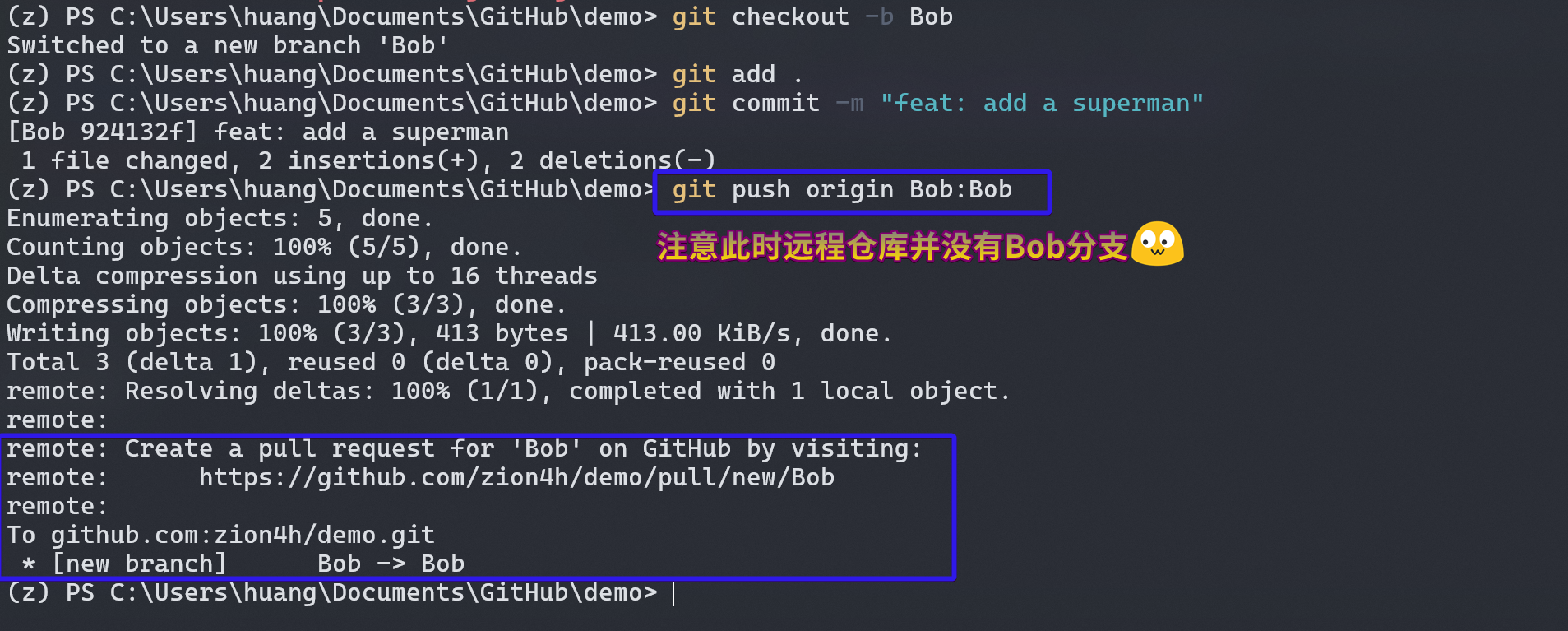
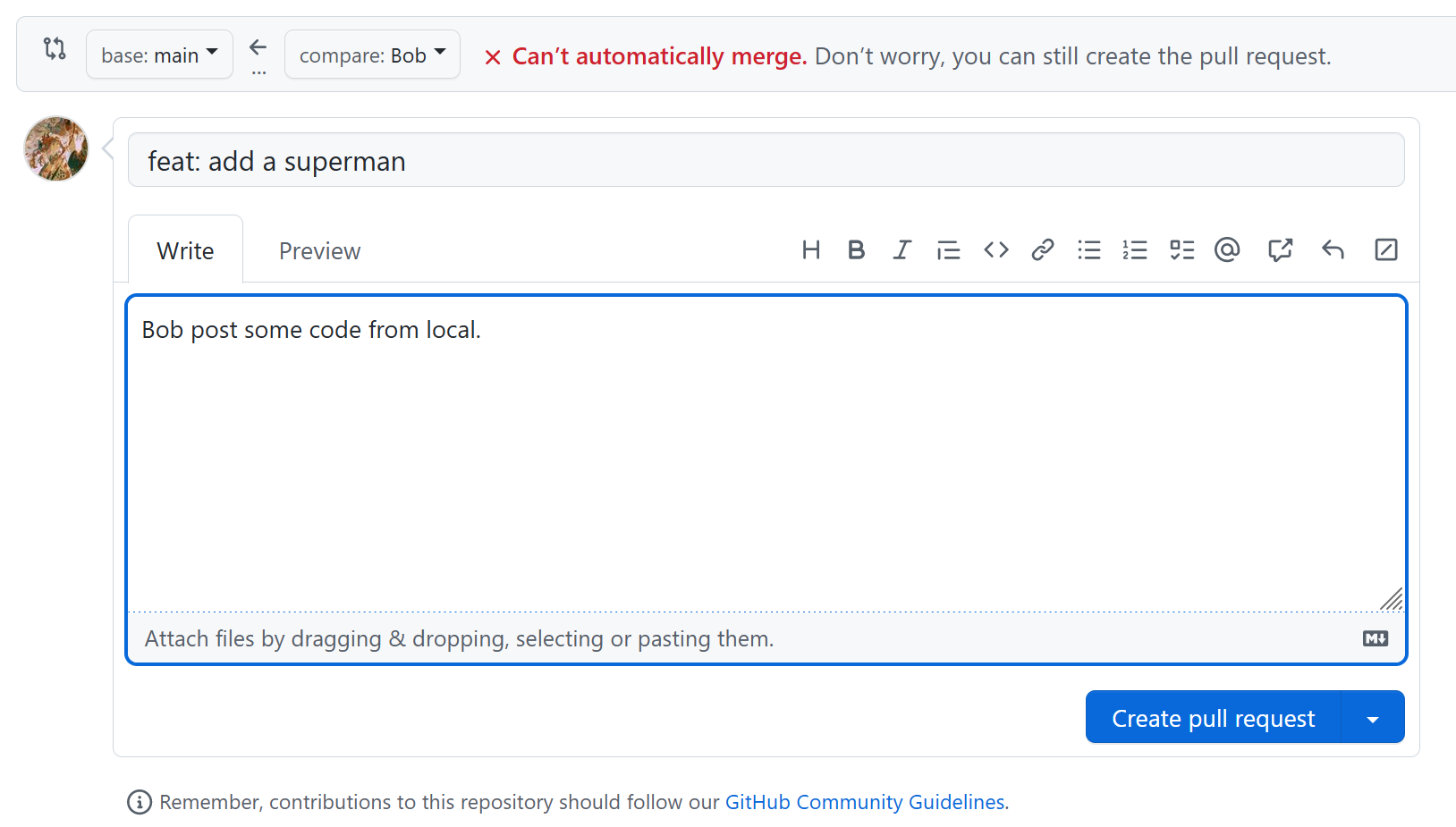
上传到远端分支 Bob 后,我们可以提交 PR,然后仓库管理员会审核,如果有冲突的代码会手动解决冲突。
参考
MIT 6.NULL 版本控制 (Git)