
MIT 6.Null 调试和性能分析
“Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” — Brian Kernighan, Unix for Beginners.
编程有一条黄金法则,“代码并不会按你所想那样运行,而只会按你所述运行”。写完代码只是编程的第一步,我们更多时间其实花在了 Debugging(调试) 和 Profiling(性能分析) 上。
Debugging
打印调试语句和日志
对于一些临时的或者 Demo 性质的程序,最简单的调试方法就是在问题代码附近不断添加打印语句,从而获得足够多信息来发现问题产生的原因。
但通常情况我们会用日志,理由如下:
- 我们可以将日志信息发到文件、socket 甚至远程服务器而不仅仅只是标准输出
- 日志支持分级,方便我们过滤输出,e.g.,
INFO、DEBUG、WARN - 对于新出现的问题,我们的日志中可能已经包含足够多信息去调试,而不用复现
这是一个用 Python 代码编写的日志打印程序:
1 | import logging |
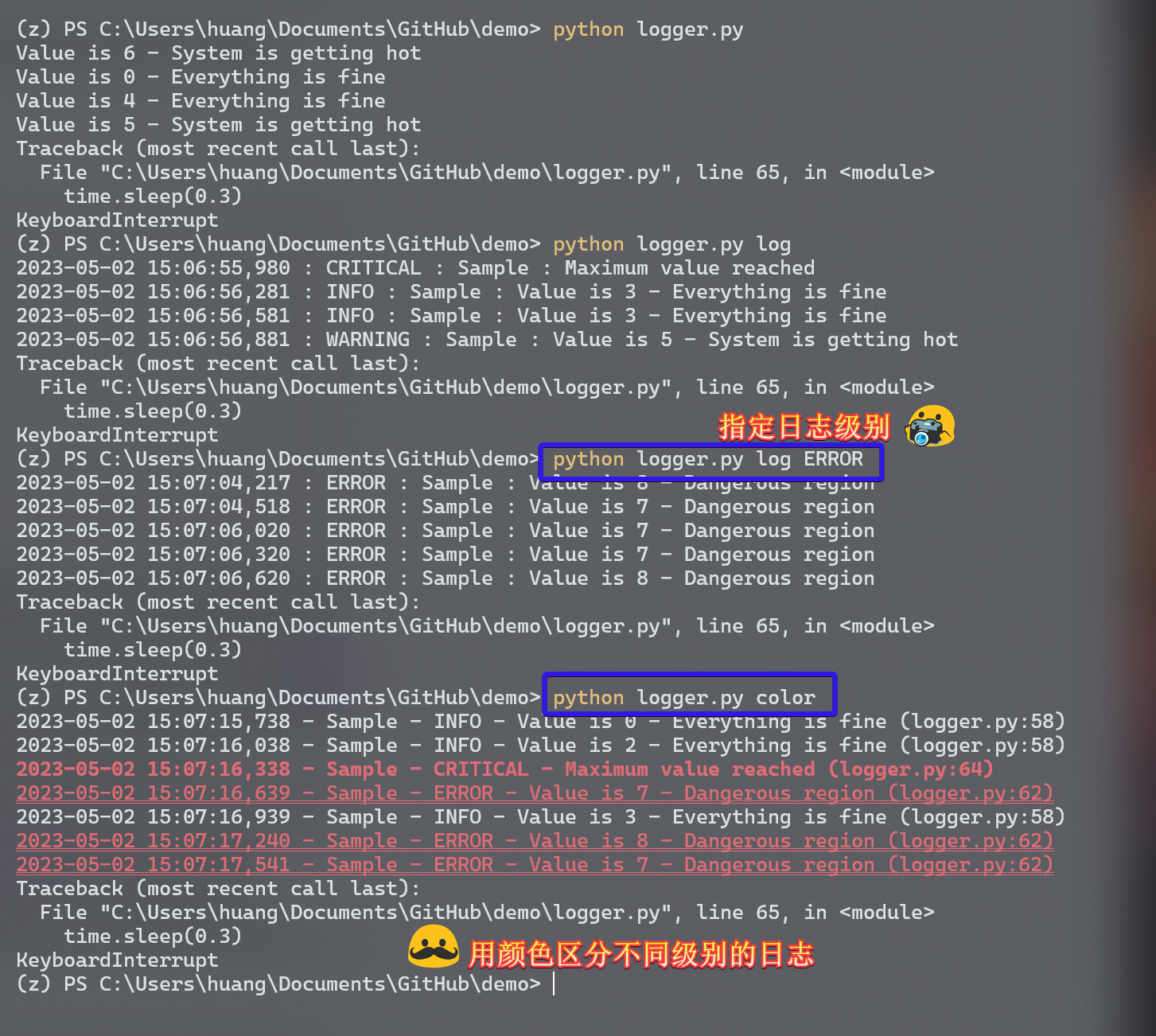
终端可以通过颜色提高可读性,像 ls 或者 grep 都使用 ANSI 转义序列 来让 shell 修改输出的颜色。e.g.,执行 echo -e "\e[38;2;255;0;0mThis is red\e[0m" 会输出一行红色的 This is red 在终端。当然,前提是这个终端支持 24-bit truecolor,像 Mac OS 的 terminal 就并不支持,需要改用只支持 16 色的 ANSI 转义序列,e.g.,执行 echo -e "\e[31;1mThis is red\e[0m"。
第三方日志
当我们在构建大型项目的时候,我们会依赖一些独立项,如 Web 服务器、数据库或者消息代理。如果程序遇到问题,我们还需要进入这些依赖项内部查看日志,因为光靠项目客户端日志提供的信息通常来说是不够的。
这些程序的日志都会把日志放到系统中,当然不同的系统存放习惯也有区别。在 UNIX 系统中,一般会放到 /var/log 目录下,比如 NGINX 将它的日志放到了 /var/log/nginx 中。
最近,很多系统开始采用 system log 来统计和整合系统上发生的所有日志消息。大多数 Linux 系统使用 systemd 来控制服务开启、关闭和运行,它的日志以一种特殊格式存放在 /var/log/journal 中,我们可以用 journalctl 命令展示内容。类似的,Mac OS 也可以用 log show 命令展示 /var/log/system.log 中的日志消息。在大部分 UNIX 系统上,你也可以用 dmsg 这个通用命令来访问日志消息。
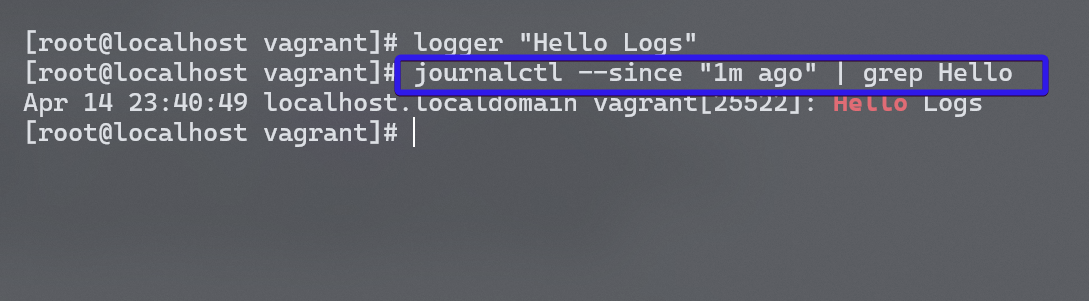
我们可以用 logger 打印消息到系统日志中,很多编程语言都有绑定对系统日志的打印。
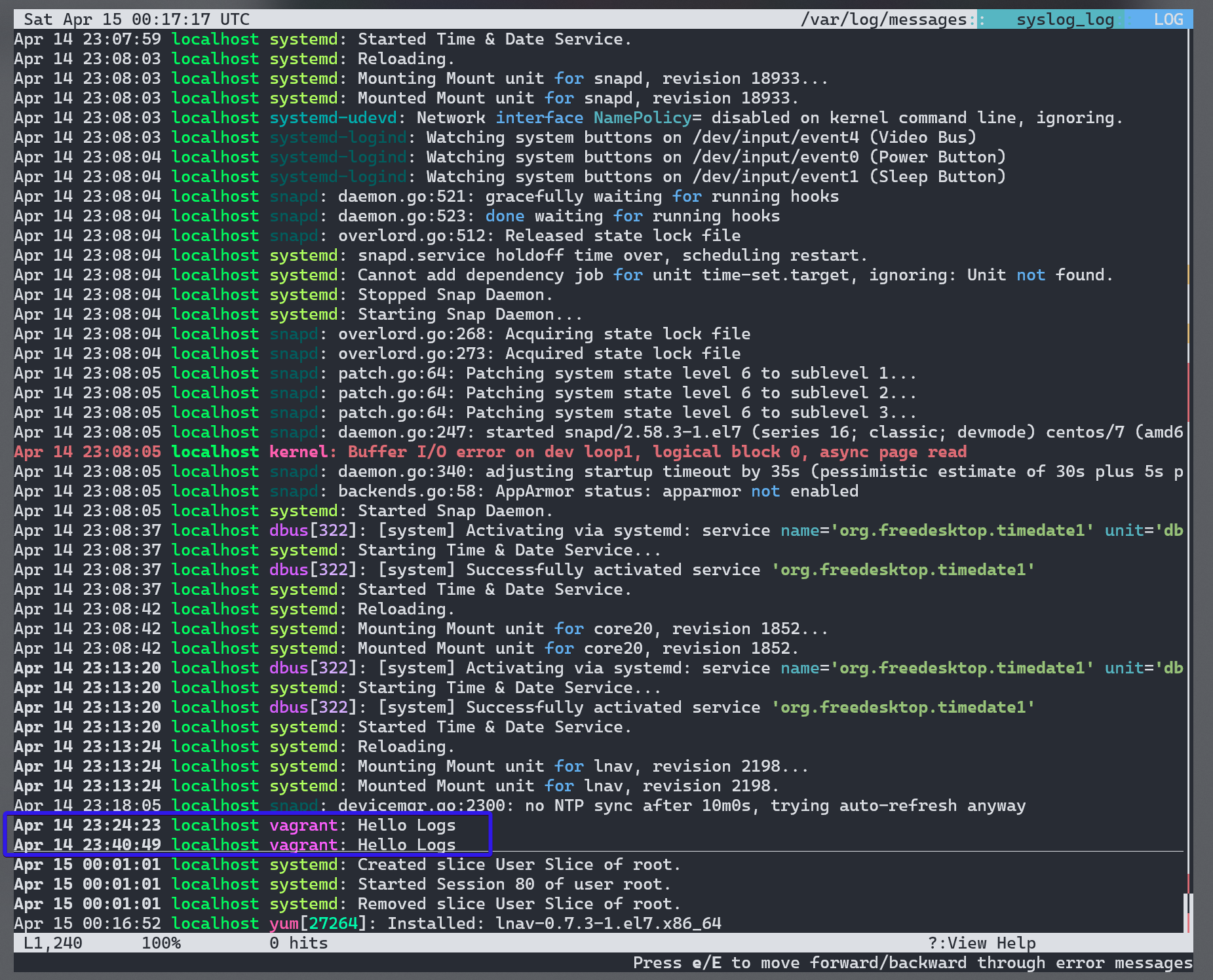
我们也可以用一些可视化效果更好的工具比如 lnav 来浏览日志,可以到 snapcraft 下载。
调试器
当打印调试也没用时,我们就该用调试器了。** 调试器(debugger)** 能够让我们交互式执行程序,具体来说它能做到:
- 到达断点时暂停
- 每次执行一步
- 当程序崩溃后能够查看变量值
- 有条件(自定)地暂停程序
许多编程语言本身自带调试器,比如 Java 自带 JDB,而 Python 则是 PDB。对于一些更底层的语言,我们很可能会用到 gdb、lldb 等调试器,它们俩主要面向类 C 语言的。
特殊工具
静态分析
静态分析程序会将源代码作为输入并使用编码规则对其进行分析以推断其正确性,不同的编程语言有不同的静态分析工具,我们只需要了解这个概念即可。
如果使用 Vim 频率较高,可以考虑加入插件 ale 或者 syntastic。
Profiling
在 Debug 结束后,尽管程序能够按照预想那样跑起来了,但它有可能占用过多不必要的 CPU 和内存资源。算法只会告诉我们如何分析时间复杂度,但并不会告诉我们真正遇到程序龟速行驶时该怎么处理。Knuth 说过 “过早优化是万恶之源”,我们应该先通过 profiler 和监视器去查看到底是哪部分代码在偷偷占用大部分资源,在这之后再考虑如何优化的问题。
时钟
和 Debug 很像,一个最简单的 profiler 可以通过时钟实现,在可疑代码段前后加上时钟,我们就能得到这部分代码的运行时间。
然而这些时钟 “墙” 可能会误导你做出错误的判断,因为进程可能会在这对时钟间等待某个事件(比如打印),而且其他进程也会在这对时钟间运行。通常 time 工具会将 Real,User 和 Sys 时间作区分,“User + Sys” 才能得到进程实际消耗的 CPU 时间,StackOverflow 上有提出 相关问题。

Profilers
-
CPU
在绝大多数时候,我们讨论的 profiler 实际指 CPU profiler。CPU profiler 有两种实现实现方式,tracing profiler 会记录程序执行的每个函数调用,而 sampling profiler 会定期侦测程序并记录程序栈。当然,它们的最终目的都是为了帮助我们了解发现程序_究竟在哪些地方耗费了大量 CPU_。 -
内存
在使用类似 C 或 C++ 编程时,内存泄漏将导致内存得不到及时释放。 -
可视化
人类都是视觉生物,谁会喜欢盯着满屏幕字母数字去绞尽脑汁翻找自己想要的信息,这种情况在没头绪的情况下会更糟(之前有过经历,只能靠前人经验去摸索,这对于程序员来说完全没道理嘛)。一个通用的解决方法是 Flame Graph 和 pycallgraph。
资源监控
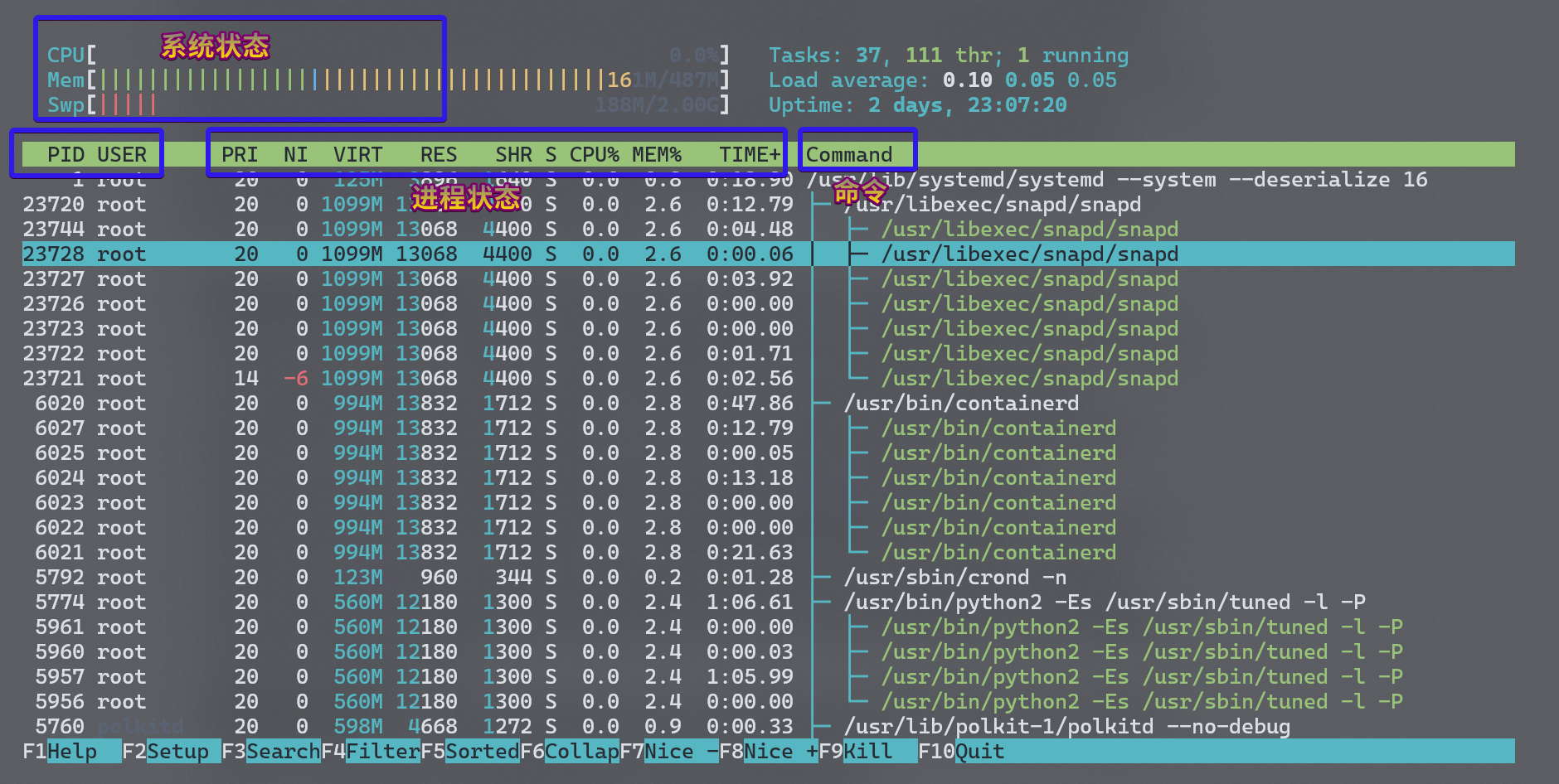
- 泛用监控:最流行的当属 htop,它本身是 top 的改进版,按
h可以查看详细使用手册。类似的,有 glances 的替品,个人觉得排版视觉更美观。 - I/O 操作:iotop
- 磁盘使用情况:df 和
du(当然,我们一般不用du,改用 ncdu) - 内存使用情况:本身
htop已经足够,但你也可以用free命令单独查看 - 打开文件:lsof
- 网络连接和配置情况:使用 ip 命令(可以看页面 examples 项),查看路由、网络设置和接口等。这里值得注意的一点是,不要再用已经被废弃的
netstat和ifconfig了。 - 网络使用情况:iftop
参考
MIT 6.Null 调试和性能分析
https://zion4h.github.io/2023/05/02/mit-6_null-debugging-and-profiling/